ARUN MADHUSDHANAN
ROBOTICS & AI | COMPUTER VISION | Ex - EXXONMOBIL | Ex - FESTO
ABOUT ME

Hi, I’m a recent graduate with a Master’s degree in Robotics, concentration in computer science, from Northeastern University. With a strong foundation in computer vision, robotics, and machine learning, I’m passionate about applying my skills to solve real-world challenges and am actively seeking full-time opportunities to contribute to innovative projects in these fields.
During my time at Northeastern, I have:
- Developed expertise in 2D and 3D Computer Vision, Machine Learning, and Robotics through various projects.
- Served as a Teaching Assistant for a graduate-level Computer Vision course.
- Completed a 6-month internship at Festo Corporation as an ML Research Engineer, where I developed a machine learning model for predicting the output parameters of a high-precision liquid dosing unit (the device is currently in patent application).
Prior to my graduate studies, I worked for 4 years at ExxonMobil as a Wells Engineer responsible for the design and selection of oil well equipment. As one of the first hires, I contributed to the growth of the Bengaluru technical center from its inception to a team of 60+ engineers.
I am excited about the opportunity to bring my diverse experience and technical skills to innovative projects in robotics, computer vision, and AI/ML. Please explore my experiences and projects below. I welcome discussions about how my background could contribute to your team's success.
EXPERIENCE
Graduate Teaching Assistant, Computer Vision
Northeastern University - Boston, MA
January 2024 - April 2024
As a Graduate Teaching Assistant for the Computer Vision course at Northeastern University, I was responsible for code review, debugging, and grading projects in C++, Python, OpenCV, and PyTorch for a cohort of 120+ students. I also held weekly office hours to mentor students on various topics. Key topics covered included:
- Image Filtering
- Content-Based Image Retrieval
- 2D Object Recognition
- Camera Calibration, KeyPoint Detectors, and Descriptors
- Stereo Vision
- Foundations of Machine Learning Methods in Computer Vision
Machine Learning Research Engineer Co-op
Festo USA - Boston
July 2023 - December 2023
At Festo USA, as part of a three-member team, my primary responsibility was to develop and implement a machine learning model to predict the output parameters of a high-precision liquid dosing unit, capable of handling volumes from microliters to milliliters. Given full autonomy in model selection and development, I successfully created an end-to-end solution that not only proved the concept but also contributed to a patented device. Here are the key areas of my work:
- Software Optimization: Enhanced the software associated with the liquid dosing unit, significantly improving system efficiency and speed. The optimized software included modules for sensing unit activation, hardware drivers for data acquisition, and components for data conversion and storage. These improvements greatly facilitated seamless experiment execution during the data collection phase.
- Machine Learning Algorithm Development: Designed and implemented a machine learning algorithm to predict the liquid dosing unit's output parameters. This involved conducting various experiments, analyzing system data, and identifying key characteristics. For model selection, I explored a range of machine learning approaches, including Long Short-Term Memory cells, Temporal Convolutional Networks, Neural Networks, and classical methods such as Decision Trees, Random Forests, AdaBoost, and Gradient Boosting. Throughout this process, I utilized various libraries including PyTorch, SciPy, Scikit-learn, NumPy, and Pandas.
- Data Labeling and Performance Metrics: Post-processed collected data to extract relevant features, created a clean dataset for machine learning tasks, and developed appropriate performance metrics to compare different models. This crucial step significantly enhanced the accuracy and reliability of the machine learning models.
- Live Inferencing Testing: Conducted live inferencing tests using the developed machine learning model on a host PC connected to the system. These tests achieved an impressive error rate of less than 2.5%, substantially exceeding the project requirement of 5% - a notable achievement considering the microliter-scale precision required.
- Patent Application: The high-quality work contributed by our team, resulted in a novel technology that is now under patent application.
Wells Engineer
ExxonMobil - Bangalore
July 2017 - June 2021
I was one of the first hires on the new Wells Team at the Bangalore Technology Centre of ExxonMobil. I played a key role in delivering high-quality work to the business unit, which significantly helped establish the team’s credibility. By the time I left to pursue higher studies, the team had grown to over 60 engineers, who were delivering exceptional work globally.
- Design and Selection of Casing Pipes: My primary responsibility was to design and select casing pipes and other equipment for installation in oil wells. I supported business divisions across the world in delivering fit-for-purpose and cost-effective tubular designs for over 15 fields and 60 wells. One of my key accomplishments was leading the beta testing of in-house casing and tubing design software, as well as third-party software DrillPlan, as a technical team lead.
- Improvement of Tubular Connection Workflow: Stewarded and improved the tubular connection workflow for business divisions globally in accordance with API 5C5, resulting in $100k immediate savings and long-term synergistic benefits. Through a study that I led, the organizational change in the tubular design process resulted in $130k immediate savings and considerable synergistic savings through process simplification, greater standardization, and inventory transferability.
- Onboarding and Mentoring: Took the initiative to onboard and mentor Wells Engineers into technical projects while providing continuous guidance to them. These achievements demonstrate my technical expertise, leadership skills, and commitment to driving results that positively impact the organization.
PROJECTS
My portfolio highlights a range of projects in Robotics, AI, and Computer Vision that I’m truly excited about. Each one reflects a problem I’ve enjoyed tackling, whether it’s coding complex algorithms from scratch, optimizing them for real-world applications, or exploring the power of sensor fusion.
Please take a look at some of my projects below.
Multi-Modal Open-Vocabulary Grasping
How can we enable robots to interpret high-level grasping instructions like "Give me an apple" instead of relying on basic commands like "Pick the object at Pose X"? How can we ensure they generalize beyond a predefined set of objects and operate in an open-vocabulary manner? How can we issue complex queries that require spatial understanding, like "Give me the fruit from the top corner"?
Introducing Multi-Modal Open-Vocabulary Grasping, a project that integrates a stack of Vision-Language Foundational Models (RAM, Grounding DINO, SAM) for scene understanding with GraspNet for grasp prediction. This enables robots to understand complex queries and interact more intelligently.
The setup works as follows:
- The scene image captured by the camera in the manipulator is processed using RAM, Grounding DINO, and SAM to extract fine-grained object masks in an open-vocabulary fashion.
- These masks are used to generate mask-labeled images.
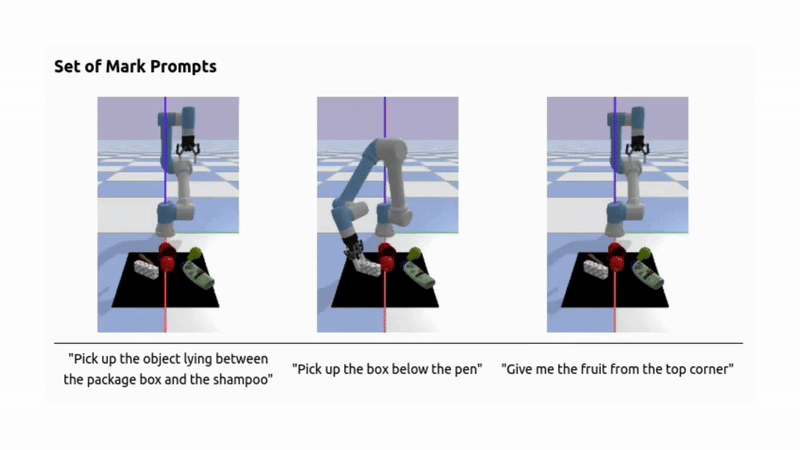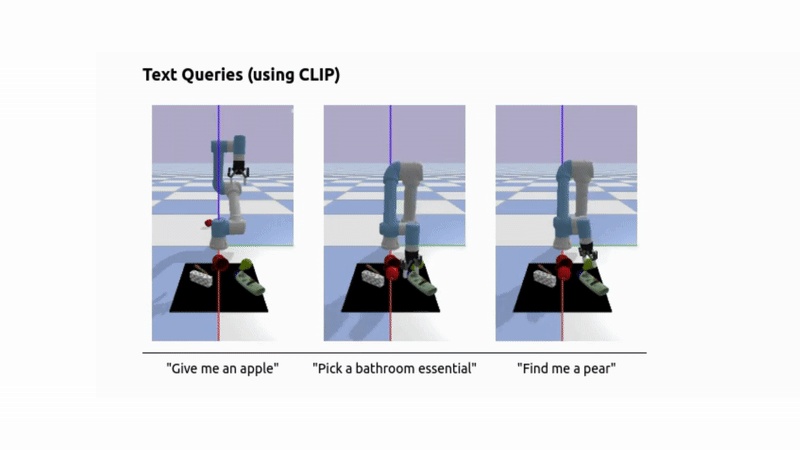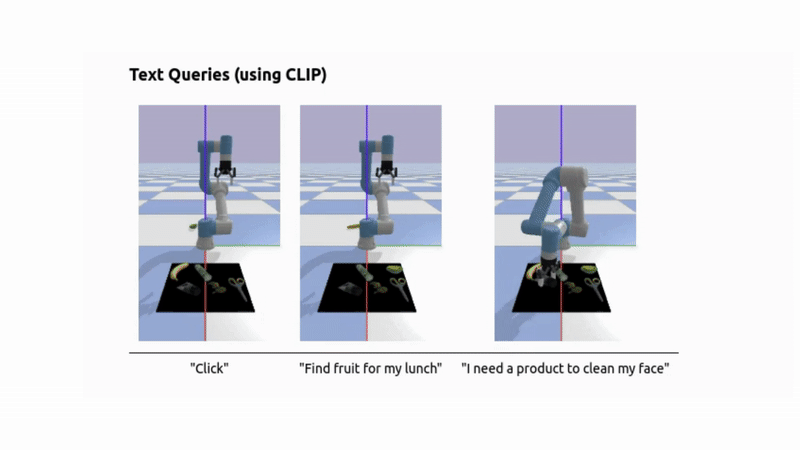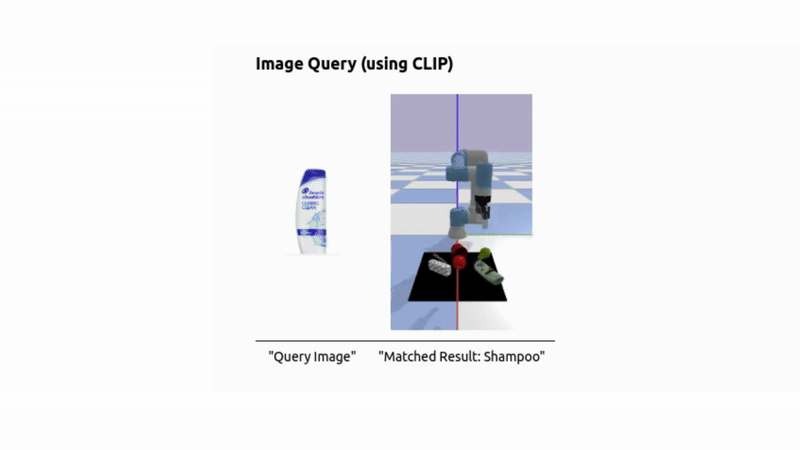
- A VLM then reasons over the marked image (Set of Mark Prompting) using the user's query and retrieves the most relevant object, enabling better spatial understanding and more accurate object identification, even from complex natural language queries. I have used LLaMA 4 Scout (currently accessed via Groq Cloud) for this purpose, but any VLM can be integrated into the pipeline.
- For simpler queries, a fallback CLIP-based retrieval system can be used instead of a full VLM.
- Once the relevant object is localized, GraspNet is used to predict viable grasp posesfor physical interaction, enabling the robot to execute the desired manipulation.
Multi-Modal Open-Vocabulary 3D Scene Understanding
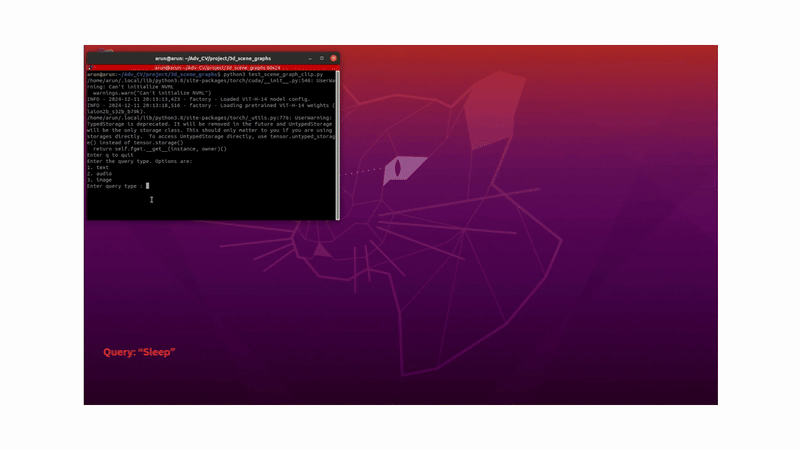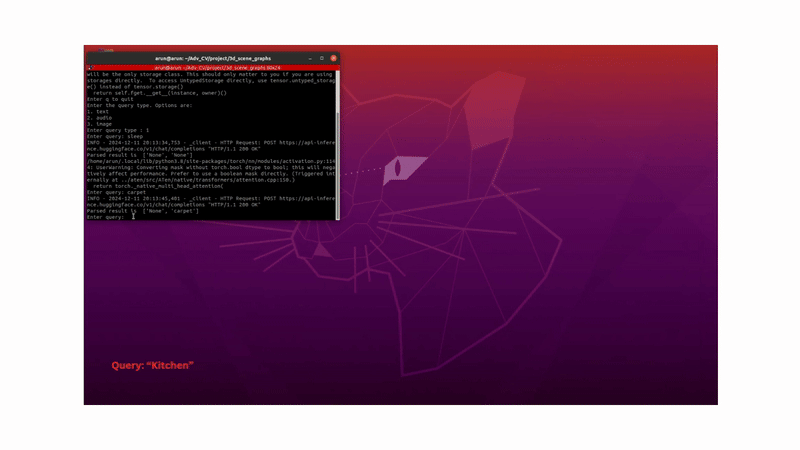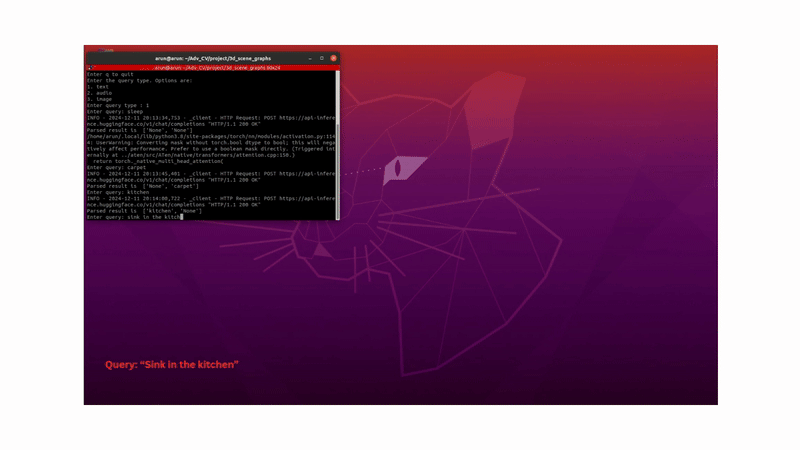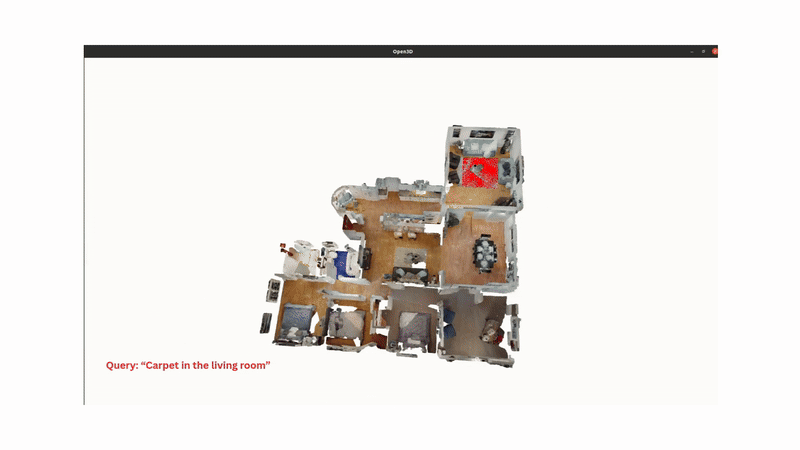
In a team of three, we built a system that enables a robot to understand natural language, image, or audio queries in an open-vocabulary setting within a 3D environment. Imagine telling a robot, “Pick up the toy from the living room”; without providing explicit 3D coordinates, the robot should be able to identify what the toy is and where it is, before navigating to it and performing the necessary actions.
Our pipeline starts with a posed set of RGB-D images used to reconstruct a 3D map of the environment. In parallel, we extract semantic features from 2D images using a stack of foundational vision models:
- RAM identifies object tags,
- which are passed as text prompts to Grounding DINO to generate bounding boxes,
- these bounding boxes are used as input prompts for SAM to extract object masks,
- and CLIP’s image encoder embeds the masked regions with semantic features.
Using depth data, we project these 2D features into 3D space to create object-specific point clouds, which are embedded and maintained in a global 3D map.
To answer natural language, image, or audio queries, we embed the input using CLIP (for text or image) or Meta’s ImageBind (for audio), and retrieve the most relevant object by computing similarity between the query embedding and the object embeddings.
To handle ambiguity, such as multiple similar objects in different rooms, we construct a hierarchical scene graph, where rooms are parent nodes and objects are children. A large language model (e.g., Qwen2-7B) parses user queries to identify relevant scene graph nodes (room), helping the robot narrow its search space intelligently.

Efficient LoRA Fine-Tuning & Inference of Quantized Qwen2-VL Models
This project focuses on the efficient fine-tuning and inference of a 4-bit quantized Qwen2-VL Vision-Language Model on a LaTeX OCR dataset using LoRA techniques. It explores two complementary approaches to low-bit fine-tuning:
- In the first approach, the model is quantized to 4-bit using the GPTQ method with the GPTQModel library. This GPTQ-quantized model is then fine-tuned using LoRA with the Hugging Face TRL library.
- In the second approach, a 4-bit quantized model is fine-tuned using QLoRA with the Unsloth library. Unsloth uses NF4 quantization (from the bitsandbytes library) to load the model in 4-bit.
Both pipelines significantly reduce resource consumption during training while maintaining strong performance. Models are evaluated using metrics such as BLEU score and Levenshtein edit distance, demonstrating substantial improvements over baseline performance.
For inference, the project uses the vLLM library to serve LoRA-adapted models efficiently without merging. Performance benchmarks such as throughput, TTFT, TPOT, and ITL are collected and visualized to compare serving efficiency across both GPTQ and QLoRA models.
The repository includes detailed installation steps and is supported by comprehensive Medium articles covering quantization, fine-tuning strategies, and vLLM-based deployment:

Optimized TensorRT Conversion for Popular Deep Learning Models
This project provides a modular codebase for converting popular deep learning models into highly optimized TensorRT engines to enable accelerated inference on NVIDIA GPUs. The models are first converted to ONNX format before being compiled into TensorRT engines. The repository supports both FP32 and FP16 precision, and the performance of the models is validated through inference using the converted TensorRT engines, demonstrating significant speed improvements.
Currently, the project supports conversion of the following PyTorch models into TensorRT engines:
- CLIP model (ViT-L/14, OpenCLIP Implementation): Enables fast image-text alignment. The converted engines demonstrate over five times speedup for both the image and text encoders.
- CoCa model (ViT-L/14, OpenCLIP Implementation): Enables fast image captioning and image-text alignment. The inference pipeline includes caption generation using greedy decoding, with all components — the image encoder, unimodal text decoder, and multimodal text decoder — running entirely within TensorRT. This approach achieves up to 7.6 times acceleration.
- YOLOv8: Enables real-time object detection. The converted TensorRT engine includes built-in EfficientNMS via TensorRT plugins for perfoming Non-Maximum Suppression. The inference time shows over three times speedup compared to the PyTorch model without NMS included. The actual speedup is even greater because the PyTorch pipeline requires an additional, separate NMS step, which is integrated within the TensorRT engine.

Time to Collision (TTC) Calculation Using Camera and LiDAR Data
The goal of this project, part of the Sensor Fusion Nanodegree at Udacity, is to detect and track 3D objects using a combination of camera and LiDAR data, and calculate the Time to Collision (TTC) with the nearest object in the ego lane. Additionally, the project focuses on accelerating the inference speed of YOLOv8 for C++ and CPU deployment.
Key aspects of the project include:
- Efficient 2D Object Detection: YOLOv8 is deployed in C++ with OpenVINO acceleration and INT8 quantization for optimized inference on CPU. The implementation supports both ONNX Runtime and OpenCV-DNN for flexibility.
- LiDAR Point Cloud Processing: Filtering and projecting 3D points onto the image plane to align LiDAR data with detected objects.
- Object Tracking: Matching YOLO-detected bounding boxes across frames using Shi-Tomasi keypoints, BRISK descriptors, and Brute-Force matching to track objects in both 2D and 3D.
- TTC Calculation: Estimating collision time using both camera-based keypoint tracking and LiDAR depth measurements.
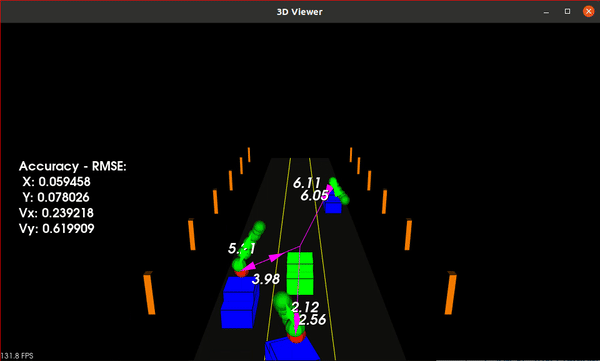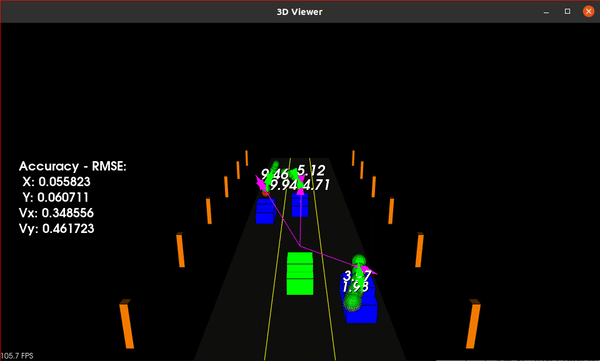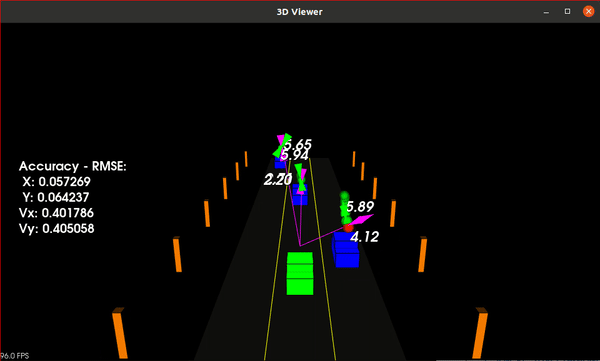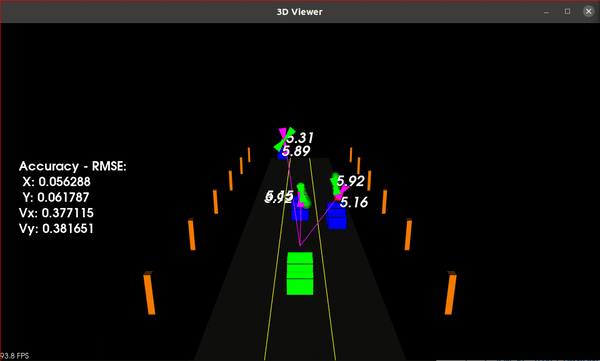
Sensor Fusion of LiDAR and Radar using Unscented Kalman Filter for Object Tracking
This project implements an Unscented Kalman Filter (UKF) for sensor fusion of LiDAR and Radar data to track moving objects around an ego vehicle. It's part of the Udacity Self-Driving Car Nanodegree Program.
Key features of this project include:
- Sensor Fusion: Combining data from LiDAR and Radar sensors for more accurate object tracking
- CTRV Motion Model: Utilization of a Constant Turn Rate and Velocity model for predicting object motion
- Performance Evaluation: Accuracy measured using Root Mean Squared Error (RMSE) over each time step and for each tracked car
- Normalized Innovation Squared (NIS): LiDAR and Radar NIS values plotted to validate filter consistency. Core algorithm in C++ with a Python wrapper using pybind11 for visualization of NIS plots
The results demonstrate the UKF's ability to track multiple traffic cars effectively, even with variable acceleration and turning rates. Most of the NIS values for both LiDAR and Radar measurements fall within the 95% confidence interval, indicating that the UKF is performing as expected.
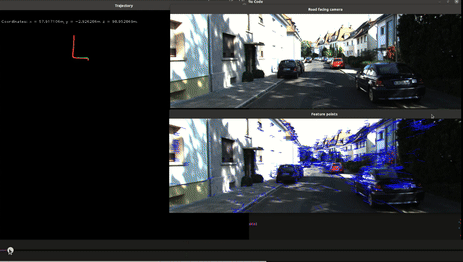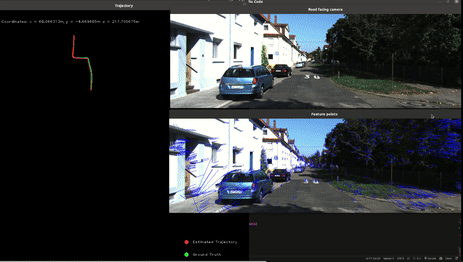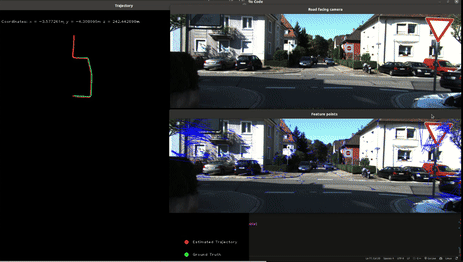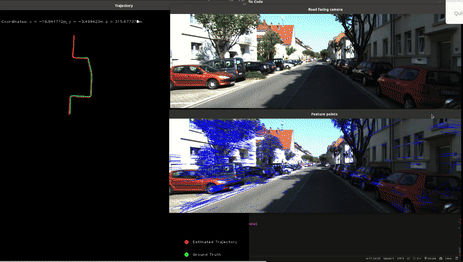
Visual Odometry
This project aimed to implement a monocular visual odometry system using OpenCV and C++. Visual odometry is a crucial technique in robotics and autonomous vehicles, enabling the estimation of camera motion from sequential images. The main goal was to solidify my understanding of feature tracking using optical flow and recovering camera poses from tracked features. The algorithm implemented consists of the following key steps:
- Feature detection using FAST (Features from Accelerated Segment Test)
- Feature tracking using Lucas-Kanade Optical Flow
- Essential Matrix computation using tracked features to recover camera pose
- Absolute scale estimation using GPS data
The primary challenge in this project was obtaining absolute scale measurements, as monocular cameras can only estimate relative poses. To overcome this, I integrated GPS information. The GPS data, provided in latitude, longitude, and altitude, was converted to UTM coordinates. The distance between consecutive UTM coordinates was then calculated and used to estimate the scale factor, allowing for accurate trajectory reconstruction.

Structure from Motion (SfM)
Structure from Motion (SfM) is a powerful technique in computer vision that enables the reconstruction of 3D structures from sequences of 2D images. This project aimed to solidify my understanding of 3D reconstruction principles, including keypoint detection and matching, camera projection matrices, stereo vision, fundamental and essential matrices, and bundle adjustment. Using a dataset provided by COLMAP, I implemented a complete SfM pipeline with the following key steps:
- Feature detection and matching using the AKAZE.
- Fundamental matrix estimation.
- Camera pose estimation.
- Triangulation to reconstruct 3D points from corresponding 2D image points.
The reconstructed 3D structure was visualized using the Open3D library.Two main challenges were addressed in this project:
- Accurate relative scale estimation between frames: Solved by storing and comparing previously triangulated 3D points with those obtained from new views.
- Outlier removal: Implemented using the RANSAC method during fundamental matrix calculation, enhancing the robustness of the reconstruction.
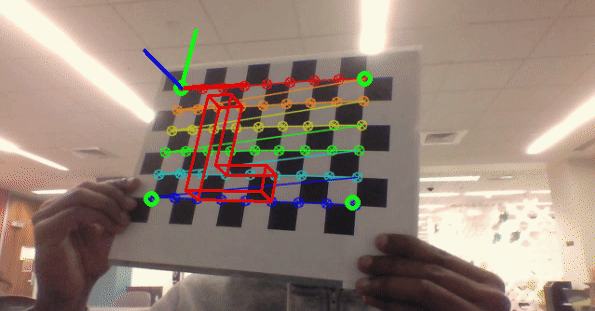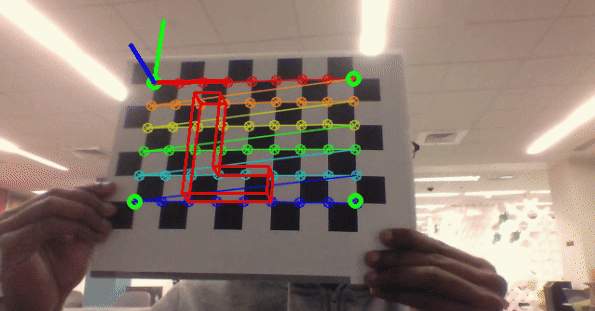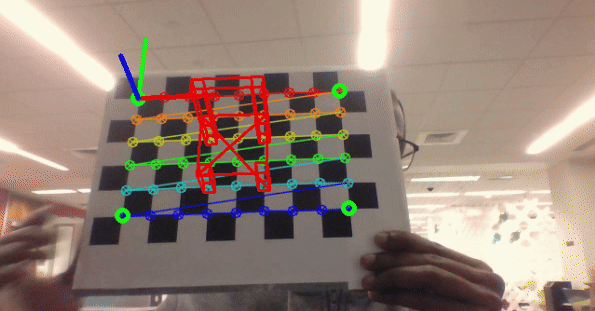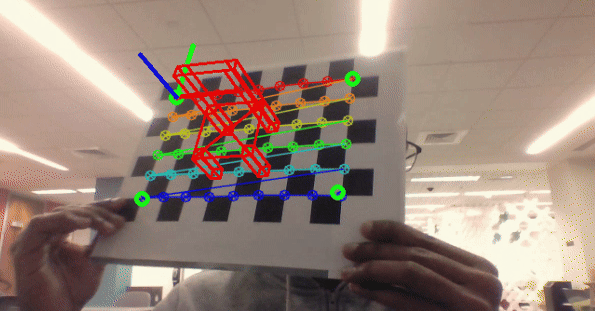
Classical Computer Vision
As part of my computer vision course at Northeastern University, I developed a series of projects that showcase various classical computer vision techniques. Implemented using C++, OpenCV, and PyTorch, these projects explore practical applications and fundamental concepts in the field.
The projects included are:
- Project 1: Real-time filtering using OpenCV and C++ on a webcam feed.
- Project 2: Content-based image retrieval using OpenCV and C++.
- Project 3: Real-time 2D object detection using OpenCV and C++.
- Project 4: Camera calibration and augmented reality using OpenCV and C++.
- Project 5: MNIST digit classification using PyTorch.
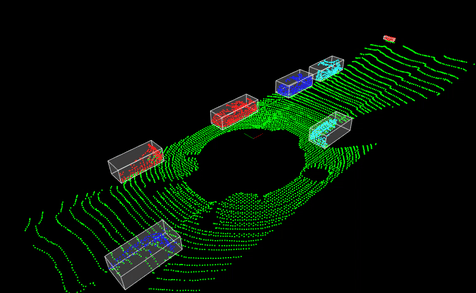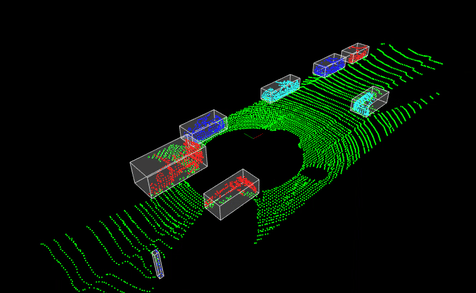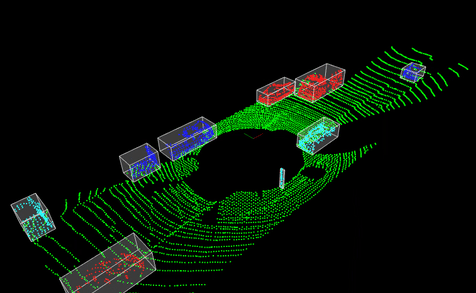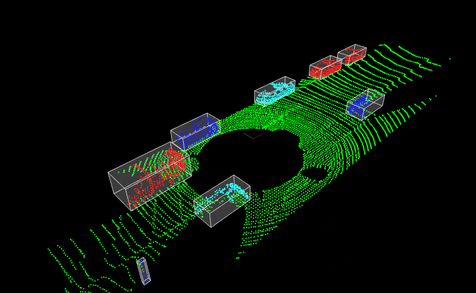
3D Point Cloud Processing using PCL
This project aimed to explore various techniques in the Point Cloud Library (PCL) for processing and analyzing 3D point cloud data, a crucial component in perception systems for autonomous vehicles and robotics. The focus was on four key operations essential for understanding and extracting meaningful information from 3D sensor data:
- Downsampling & Filtering: Implementing techniques like voxel grid filtering to reduce point cloud density while preserving important features.
- Segmentation: Utilizing algorithms such as RANSAC to separate the ground plane from objects of interest.
- Clustering: Employing methods like Euclidean cluster extraction to group points that likely belong to the same object.
- Bounding Box Creation: Implementing techniques to encapsulate clustered objects for further analysis, which is vital for object detection and tracking in autonomous systems.
NeRF from Scratch
This project is a PyTorch implementation of Tiny NeRF, a simplified version of the Neural Radiance Fields (NeRF) model. The model is trained on images of a Lego set to render a 360-degree view of the scene. Key simplifications include the use of 3D spatial coordinates instead of the original 5D input, and uniform sampling along the ray instead of hierarchical sampling. The following steps were taken in this implementation:
- Compute the camera rays and sample 3D points along the rays
- Positionally encode the sampled points and feed them into the network to compute the color and volume density (σ) for each point
- Use the volume density (σ) to compute the compositing weights of samples on a ray
- Compute the pixel color by integrating the colors of all samples along a ray
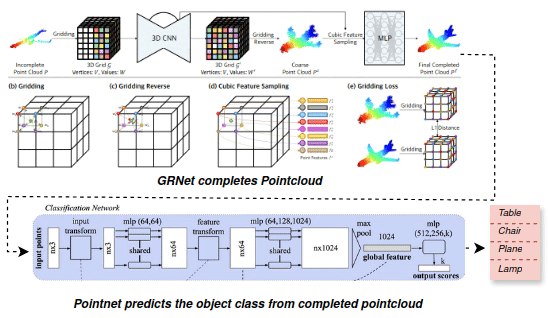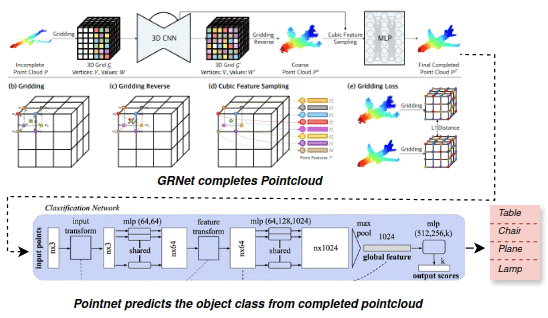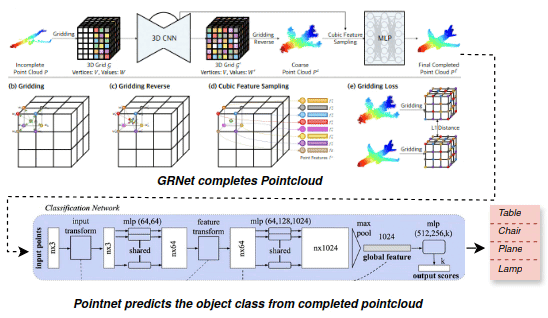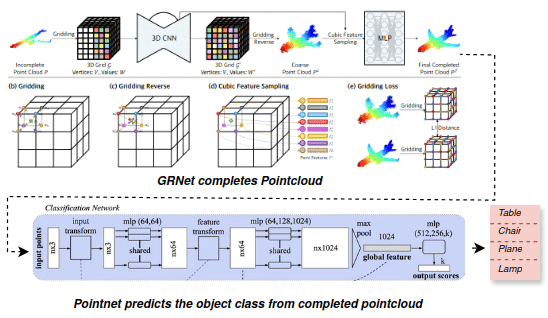
3D Object Detection From Partial Point Clouds
Point clouds are widely used as geometric data in various deep learning tasks like object detection and segmentation. However, in real-world scenarios, partial point clouds are often encountered due to limitations in sensors, occlusions, and other factors. The classification of objects from partial point clouds is a difficult task because of the sparsity, noise, and lack of complete representation of objects. This project aims to create a 3D object classification system that can classify objects from partial point clouds. To overcome the challenges, the GRNet neural network architecture is used to predict the missing data and complete the partial point clouds, which are then processed by PointNet, a deep learning framework that directly handles raw point clouds for object classification. The proposed method in this project performs equally or better than SOTA PointNet++.

Optical Flow Estimation
Optical flow estimation has found applications in various computer vision applications like object detection and tracking, movement detection, robot navigation, and visual odometry. This project presents a comprehensive study comparing the performance of both the classical and deep learning approaches for estimating dense optical flow. We used the Farneback method as a representative of classical techniques and FlowNet 2.0 as a representative of deep learning-based methods. Our experimental results highlight the performance comparison of both methods on a defined dataset using appropriate metrics - L1 error, Average end point error, and Average angular error. The results show that FlowNet 2.0 provides significantly better results than the Farneback Algorithm.
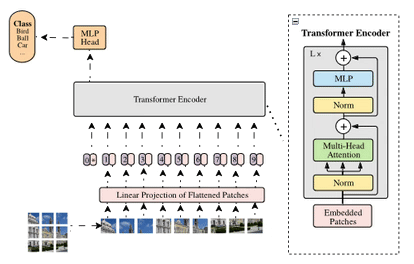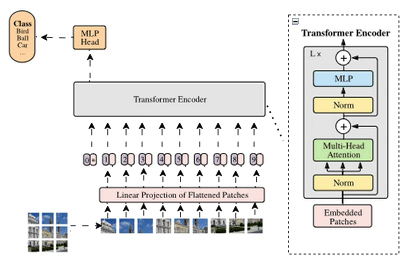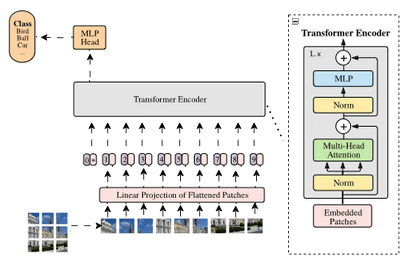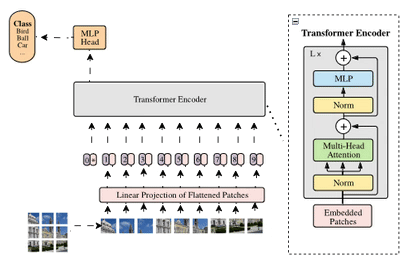
Vision Transformer (ViT) from Scratch
This project presents an unofficial PyTorch implementation of the Vision Transformer (ViT) model, inspired by the groundbreaking paper "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale". The primary objective was to create a clear, well-documented implementation that serves as both a functional model and an educational resource.
Key features of this project include:
- A from-scratch implementation of ViT using PyTorch
- Detailed comments explaining each component of the architecture
- Visualization of attention maps to provide insights into the model's decision-making process
- Exploration of the transformer architecture's potential in computer vision tasks
This implementation not only demonstrates the power of transformer models in image recognition but also serves as a valuable tool for understanding and learning about this innovative approach to computer vision.
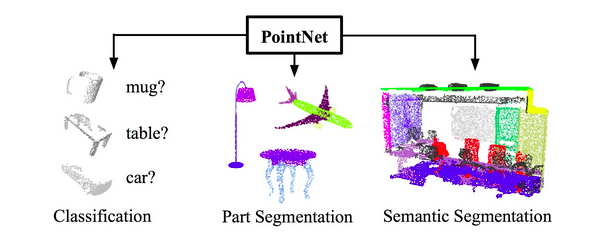
PointNet from Scratch
This project stemmed from my personal interest in coding architectures from scratch. PointNet is a pioneering model in the field of 3D point cloud processing, designed for tasks such as classification and segmentation of 3D shapes. I aimed to build it from the ground up to deepen my understanding and create a readily available source for future projects, minimizing reliance on the authors' specifications. I implemented both classification and part segmentation using ShapeNet data, achieving results comparable to the original authors' implementation.
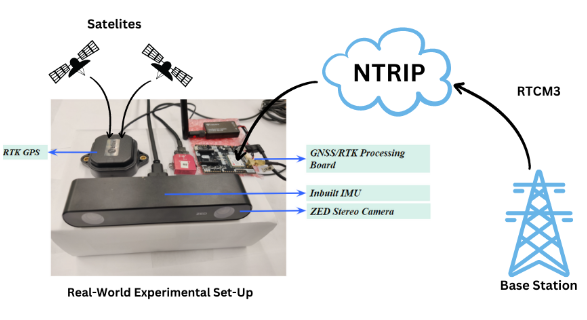
State Estimation: Challenges in Mixed Environments
In this project, my team and I explored the common challenges of global state estimation using SLAM pipelines across diverse environments, including outdoor scenarios, indoor settings, and transitions between indoor and outdoor environments.
For the Visual-Inertial Navigation System (VINS) category, we conducted experiments using ORB SLAM 3 in carefully selected areas around our university, pushing each sensor to its failure limits.
Additionally, we evaluated the accuracy of GPS trajectories in outdoor environments by collecting data using RTK GPS, enhanced with NTRIP (Network Transport of RTCM via Internet Protocol) technology. The RTK GPS method improves measurement accuracy by receiving GPS correction signals from a base station, while the NTRIP method transmits GPS correction signals from a remote base station via the internet, eliminating the need for our own base station setup.
To assess the improvements from integrating GPS with a VINS system for state estimation, we evaluated the state-of-the-art GVINS algorithm on a complex dataset released by HKUST University.